February 16, 2018
Optimize Namespaces to Reduce XML Size
Make your XMLs smaller by eliminating duplicate namespaces.

Why XML Size Matters
Size of payload XML can make a service slow in few ways:
- Service parses the XML slower
- Service transforms the XML slower
- Service serializes the XML slower before sending them over the wire
- The XML travels over the wire slower
- If the XML is stored (in cache or on disk), its serialized version takes longer to save or read
Generally, we want our XMLs to be smaller if we need our services be faster.
Why are XMLs So Big?
Let’s admit it, XML is not the most efficient format. It has a markup that duplicates the name of the tag for closing it - and it’s a waste. But we cannot do much about that.
In some cases, however, XMLs are merely not serialized optimally. They could be much smaller. Let’s review one of the common causes and learn how to fix it.
One Possible Reason: Duplicate Namespaces
When we build XML from multiple sources in OSB composite services, the elements will retain their original namespace attributes. The same namespace may be declared in the parent axis already but, when serialized, XML stubbornly keeps its redundant declaration.
It looks like this:
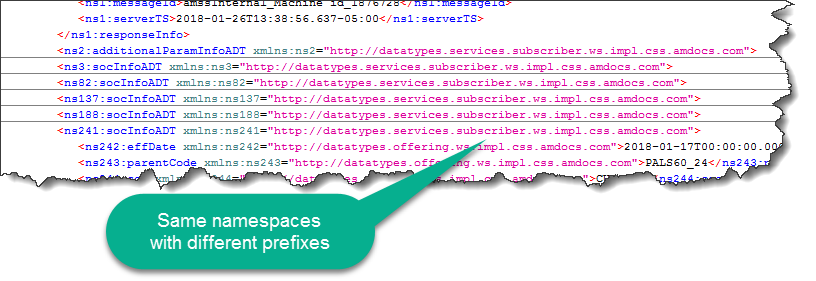
Not only it increases the size of XML, but it also makes the clients’ parser work harder by introducing a large number of unnecessary namespaces.
How Much Can be Saved
In some cases, I was able to reduce XML from 3MB to 1.5MB - simply by removing all duplicate namespaces.
Processing speed should also improve, though I did not measure that.
How to Optimize the Namespaces
The fix is simple. Use a Java callout to traverse the XML tree. Find all the unique namespaces and add them as xmlns attributes to the top element.
Then remove all xmlns elements from all other elements in the tree. Done! Each namespace is defined only once.
The code that does that is below.
Leave Default Namespace Alone
Note of caution: I’ve tried to go an extra mile and specify the most used namespace as the default. I thought that least prefixes make the on-the-wire size smaller. That was true, but XMLs built from multiple sources may contain their own default namespaces in each part, and they conflict.
Don’t mess with the default namespace.
Abort! Abort!
But not so fast.
Consider this XML:
<foo xmlns:aaa="http://bbb">
<bar name="aaa:123">...</bar>
</foo>
The attribute name has a value with a prefix. The prefix matches the namespace http://bbb prefix, but is it really the namespace prefix?
In general, we cannot know. It could be a QName for {http://bbb,123}, or it could be just a literal name aaa:123.
However, if we optimize the namespaces, we would assign http://bbb a different prefix. Then we risk breaking the document’s meaning because of the aaa: prefix is
not referring to any namespace anymore.
There is only one well-known attribute that we can safely update: it is xsi:type. We know it contains an XSD-prefixed type name.
See more details in this StackOverflow question.
Because of this corner case (and after getting a PROD defect open for my code :-( ), I have updated the code to work by the following rules when it encounters an attribute that has a prefixed value:
- For xsi:type attribute, update the attribute value’s prefix to match the new prefix for
http://www.w3.org/2001/XMLSchema. - If in the current context there IS NO namespace with a matching prefix, the value is considered standalone and left as is.
- If in the current context there IS a namespace with a matching prefix, we cannot tell if the attribute value is standalone or QName, and so we cancel the processing and leave the document as is. The document is not modified.
For some percent of the documents the optimization doesn’t happen. That’s OK with me because my code rarely receives documents with such ambiguously prefixed attributes. YMMV.
The Code
Here comes the code.
Call optimizeNamespaces(xml) from an OSB Java callout and your XML will be minimized. The return value is the same XmlObject.
If you have a DOM Node instead of XmlObject, there is an overloaded version of the same method.
The operation is quite quick - it takes only about 200ms for a 3MB XML and almost nothing for smaller XMLs.
package com.mockmotor.xq;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.xmlbeans.XmlObject;
import org.w3c.dom.Attr;
import org.w3c.dom.Element;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class XmlNamespaceOptimizer {
/**
* Reduces the size of serialized XML by moving all NS definition to the top element
* (i.e. no redundant NS declaration) and using one-letter namespace names.
*
* For some large XMLs the reduction can be up to 50%.
*
* Note that some attributes may contain a prefixed value, e.g. name="foo:bar".
* There is no generic way to tell if "foo:" is a namespace prefix, or an unrelated
* value part. See more details here:
*
* https://stackoverflow.com/questions/50234727
*
* For this reason, when the code encounters an attribute that looks like a QName, it does the following:
*
* 1. For xsi:type attribute, update the attribute value's prefix.
* 2. If in the current context there IS NO namespace with a matching prefix,
* the value is consider standalone and left as is.
* 3. If in the current context there IS a namespace with a matching prefix, we cannot
* tell if the attribute value is standalone or QName, and so we cancel the processing
* and leave the document unmodified.
*
*/
public static XmlObject optimizeNamespaces(XmlObject gasf) throws Exception {
try {
Node dn = gasf.getDomNode();
dn = dn.getFirstChild();
optimizeNamespaces(dn);
} catch(Exception ex ) {
ex.printStackTrace();
}
return gasf;
}
public static void optimizeNamespaces(Node dn) throws Exception {
// URI -> prefix
Map<String,String> context = new HashMap<String,String>();
// URIs -> prefix
Map<String,String> allKnown = new HashMap<String,String>();
List<Action> actions = collectNamespaces(dn,context,allKnown);
// add known namespaces to top element
addNamespacesToTopElement(dn,allKnown);
// all removals first
for(Action action: actions) {
if( action.newValue == null ) {
((Element)action.parent).removeAttributeNode((Attr) action.node);
}
}
// all update prefix then
for(Action action: actions) {
if( action.newValue != null ) {
Attr attr = (Attr) action.node;
attr.setValue(action.newValue);
}
}
}
private static final String PREFIXES = "qwertyuiopasdfghjklzxcvbnm";
private static String nextPrefix(int n) {
int digit = n/PREFIXES.length()+1;
char c = PREFIXES.charAt(n % PREFIXES.length());
String prefix = ""+c+(digit>1?digit:"");
n++;
return prefix;
}
private static void addNamespacesToTopElement(Node dn,Map<String,String> allKnown) {
Node top = dn;
if( top.getNodeType() != Node.ELEMENT_NODE ) {
top = dn.getChildNodes().item(0);
}
Element el = (Element) top;
for(String uri: allKnown.keySet() ) {
String prefix = allKnown.get(uri);
el.setAttribute("xmlns:"+prefix,uri);
}
}
private static List<Action> collectNamespaces(Node node,Map<String, String> context,Map<String,String> allKnown) {
List<Action> ret = new ArrayList<Action>();
if( node == null ) return ret;
if( node.getNodeType() != Node.ELEMENT_NODE ) return ret;
Element el = (Element) node;
// get namespace attributes xmlns:xxx
NamedNodeMap attrs = node.getAttributes();
if( attrs != null ) {
// process all xmlns attributes
for( int a=0; a<attrs.getLength(); a++ ) {
Node item = attrs.item(a);
String name = item.getNodeName();
String val = item.getNodeValue();
if( name.startsWith("xmlns") ) {
if( !allKnown.containsKey(val) ) {
allKnown.put(val,nextPrefix(allKnown.size()));
}
String prefix = name.substring("xmlns".length());
if( prefix.startsWith(":") ) prefix = prefix.substring(1);
context.put(val, prefix);
// to remove later
ret.add(new Action(node,item,null));
}
}
// process all non-xmlns attributes
for( int a=0; a<attrs.getLength(); a++ ) {
Node item = attrs.item(a);
String name = item.getNodeName();
String val = item.getNodeValue();
if( !name.startsWith("xmlns") ) {
String ownNs = countOwnNamespace(item, allKnown);
String[] s = val.split("\\:",2);
String valPfx;
String valVal;
if( s.length == 1 ) {
valPfx = null;
valVal = s[0];
} else {
valPfx = s[0];
valVal = s[1];
}
String valNs = null;
for(String ns: context.keySet()) {
String nsp = context.get(ns);
if( valPfx != null && valPfx.equals(nsp) ) {
valNs = ns;
break;
}
}
// update xsi:type prefix
if( "http://www.w3.org/2001/XMLSchema-instance".equals(ownNs) &&
"type".equals(item.getLocalName()) ) {
Attr attr = (Attr) item;
String newVal = allKnown.get("http://www.w3.org/2001/XMLSchema")+":"+valVal;
ret.add(new Action(node,attr,newVal));
}
else if( valNs != null ) {
// The attribute has a prefix matching a namespace in the context
// Can't tell should we renamed the prefix or leave it as is
// Abort the optimization
throw new RuntimeException("Unrecognized attribute "+name+"'s value "+val+
" has a prefix matching NS "+valNs);
}
}
}
}
countOwnNamespace(node, allKnown);
NodeList cns = node.getChildNodes();
if( cns != null ) {
for( int i=0; i<cns.getLength(); i++ ) {
Node cn = cns.item(i);
HashMap<String, String> nestedContext = new HashMap<String,String>(context);
List<Action> actions = collectNamespaces(cn, nestedContext, allKnown);
ret.addAll(actions);
}
}
return ret;
}
private static String countOwnNamespace(Node item,Map<String,String> namespaces) {
String ownNs = item.getNamespaceURI();
if( ownNs == null ) return null; // don't mess with default namespace
if( ownNs.trim().isEmpty() ) return null;
if( !namespaces.containsKey(ownNs) ) {
namespaces.put(ownNs,nextPrefix(namespaces.size()));
}
return ownNs;
}
private static class Action {
public Node parent;
public Node node;
public String newValue;
public Action(Node parent,Node node,String newValue) {
this.parent = parent;
this.node = node;
this.newValue = newValue;
}
}
}

About Me
My name is Vladimir Dyuzhev, and I'm the author of GenericParallel, an OSB proxy service for making parallel calls effortlessly and MockMotor, a powerful mock server.
I'm building SOA enterprise systems for clients large and small for almost 20 years. Most of that time I've been working with BEA (later Oracle) Weblogic platform, including OSB and other SOA systems.
Feel free to contact me if you have a SOA project to design and implement. See my profile on LinkedIn.
I live in Toronto, Ontario, Canada. ![]() Email me at info@genericparallel.com
Email me at info@genericparallel.com