June 8, 2015
Graceful Degradation for OSB

You should realize that not all services are equally useful.
Some, like submitting orders, are directly generating revenue to your company.
Some others, like getting orders history, while important, can be sacrificed to let orders get submitted.
When the system is under a higher then usual load, how can we dynamically shutdown non-essential services to release more resources to the essential ones?
Our Playground: the Orders Service
For our experiments, I’m going to use a mock service that has two operations:
| SubmitOrder | A critical operation. We must not let it fail. |
| GetOrdersHistory | A non-critical operation. We can let it fail if that releases resources for SubmitOrder. |
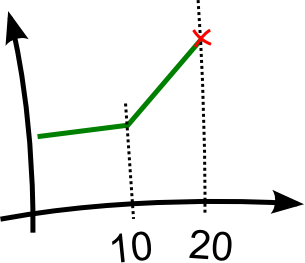
This service has a common capacity profile:
- While it is hit by less than 10 concurrent requests, its response time is constant.
- When it is hit by more than 10 concurrent requests, its response time grows propotionally.
- Any request above 20th just fails due to lack of resources.
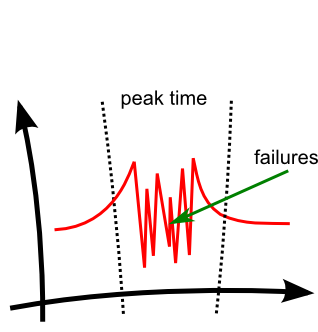
When traffic increases, the SubmitOrder and GetOrdersHistory are both called, and both are taking the service’s resources. At some point the service begins to fail, and it happens equally to SubmitOrder and GetOrdersHistory.
Our Goal: Maximize SubmitOrder's Success Rate
But remember that SubmitOrder actually makes us money, while GetOrdersHistory is a nice to have functionality. We have to maximize the success rate of SubmitOrder calls.
What we want to achieve is this:
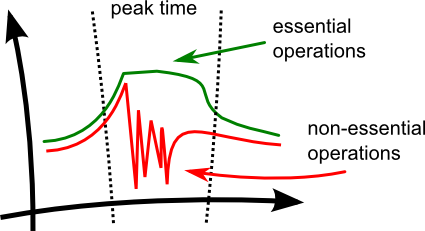
Ideally, SubmitOrder should have 100% success rate, while for GetOrdersHistory anything above 0% would do.
Baseline
To have a baseline to compare with, I have made a JMeter project with two load profiles.
Normal load is ramping up to 30 threads in 20 seconds and each thread performs 20 requests (either SubmitOrder or GetOrderHistory).
Overload is ramping up to 40 threads in same 20 seconds and each thread performs 20 requests.
The difference seems small, but it is just enough to trigger DoS on the backend service.
| Normal traffic | Overload | |||
|---|---|---|---|---|
| Operation | Average response time, ms | Success rate, % | Average response time, ms | Success rate, % |
| SubmitOrder | 1036 | 100 | 1169 | 70 |
| GetOrdersHistory | 270 | 100 | 290 | 72 |
Attempt #1: OSB Throttling (DOESN'T WORK)
OSB throttling is applied at the Biz service and limits the number of concurrent requests in a progress. It cannot selectively suppress GetHistoryOrders only, and it hence cannot help with our goal.
But for the sake of it, lets apply throttling 15 to the Biz service and see how it affects the scenarios. (There is no point to set throttling higher, e.g. to 20, because the backend service itself fails at 20).
| Normal traffic | Overload | |||
|---|---|---|---|---|
| Operation | Average response time, ms | Success rate, % | Average response time, ms | Success rate, % |
| SubmitOrder | 944 | 88 (-12) | 1018 | 62 (-8) |
| GetOrdersHistory | 240 | 85 (-15) | 255 | 71 (-1) |
The result is far from desired.
The biggest negative effect is that even during the normal load the throttling kills some of the SubmitOrder requests.
Nor does throttling help during the overload time. It actually affects SubmitOrder more than the optional GetOrdersHistory - 8% reduction in success rate vs 1%.
The only positive side is that the requests that did succeed have completed faster. This is because the excess requests were failing fast, even before leaving ESB, releasing more resources for the backend service.
Bottom line: OSB throttling is useless for graceful degradation.
Attempt #2: DIY Priority Throttling (DOES WORK)
Alright, if the built-in functionality cannot help us, let’s make our own.
Throttling is just a counter. It can be implemented in many different ways. What’s critical for us is that SubmitOrder, even if it exceeds the counter’s maximum, should go through.
I made a Java callout class to support this logic:
Every request obtains a lease from the counter. The initial value of the counter is 1000, but every lease reduces it by the request’s weight (a configurable value, the heavier the request the large the weight).
Essential requests are allowed to send the counter into negative, but regular requests get an exception if they do that.
When the request is complete (successfully or with a fault), the release() method is called with the same weight to reduce the counter.
The throttling counters are identified by name. For example, for my test I use ‘OrderService’. The names allow to have more than one throttling counter per OSB domain.
package com.genericparallel;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.atomic.AtomicInteger;
public class GracefulDegradationThrottle {
private static Logger logger = Logger.getLogger("graceful");
private static ConcurrentHashMap thresholds = new ConcurrentHashMap();
/**
* Obtain a lease to pass. High priority calls always get a lease, even if
* the remainder is zero.
*
* @param throttlingGroup
* The name of throttling group.
* @param isHighPriority
* True if the call is a necessary one, false if optional.
* @param weight
* The call weight. The initial threshold counter is 1000, the
* weight is subtracted from it.
*/
public static void lease(String throttlingGroup, boolean isHighPriority, int weight) {
AtomicInteger counter = getCounter(throttlingGroup);
int cnt = counter.addAndGet(-weight);
if ( cnt < 0 ) {
// pass high-priority call anyway
if( isHighPriority ) {
String msg = "Threshold is reached for " + throttlingGroup+"; allowing an essential call";
logger.warning(msg);
return;
}
// reject the non-essential calls and restore the counter
try {
String msg = "Threshold is reached for " + throttlingGroup+"; rejecting a non-essential call";
logger.warning(msg);
throw new RuntimeException(msg);
} finally {
counter.addAndGet(weight);
}
}
}
/**
* Releases the lease.
*
* @param throttlingGroup
* The name of the throttling group.
* @param weight
* Weight to release.
*/
public static void release(String throttlingGroup, int weight) {
AtomicInteger counter = getCounter(throttlingGroup);
counter.addAndGet(weight);
}
// made synchronized to make sure the creation of the counter is not having a race condition
private synchronized static AtomicInteger getCounter(String throttlingGroup) {
AtomicInteger counter = thresholds.get(throttlingGroup);
if (counter == null) {
counter = new AtomicInteger(1000);
thresholds.put(throttlingGroup, counter);
String msg = "Created threshold for " + throttlingGroup+" = "+1000;
logger.info(msg);
}
return counter;
}
}
Then we need to call lease() on the request pipeline and release() on response pipeline and in the error handler:
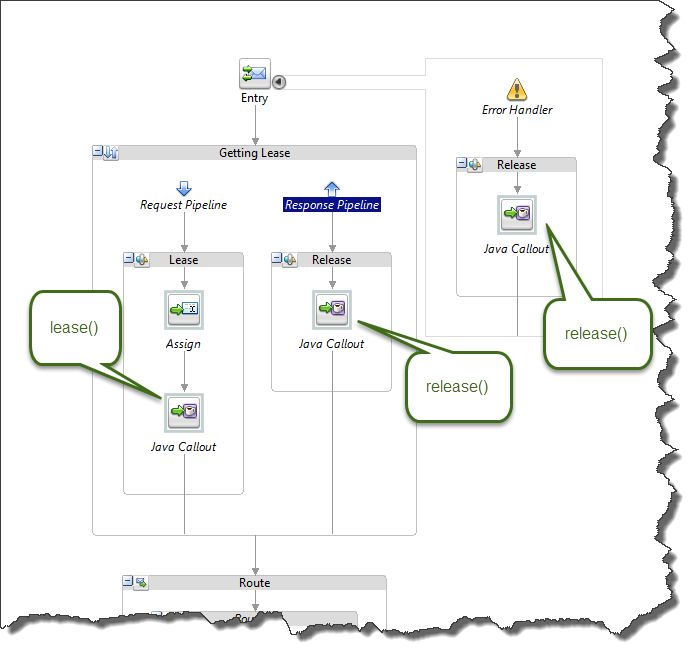
Now we have to choose weight values for SubmitOrder and GetOrdersHistory so that during the normal load our throttling does not block any requests, and during the excessive load the blocking kicks in. It could be done either estimating the values on the back of a napkin, or by running a few load tests. I chose to find the fitting values experimentally.
The weight values that best worked for my service and load profiles are 58 for SubmitOrder and 20 for GetOrderHistory.
The call to lease() then is:
| Operation | lease() | release() |
|---|---|---|
| SubmitOrder | lease('OrderService',true,58) | release('OrderService',58) |
| GetOrdersHistory | lease('OrderService',false,20) | release('OrderService',20) |
When executed the same tests with the priority throttling in place, I’ve got the following results. As you can see, the success rate for SubmitOrder is much higher (96%) during the high load, at a cost of some reduction of GetOrdersHistory - i.e. just as planned:
| Normal traffic | Overload | |||
|---|---|---|---|---|
| Operation | Average response time, ms | Success rate, % | Average response time, ms | Success rate, % |
| SubmitOrder | 1036 | 100 | 1246 | 96 (+26) |
| GetOrdersHistory | 270 | 100 | 275 | 60 (-12) |
Tuning the relative weights, we can even achieve 100% SubmitOrder success rate, but at a cost of some GetOrdersHistory failures during the normal load.
And, of course, if the high traffic volume increases even more, the priority throttling won’t be able to help either. But nothing else probably would.
Nevertheless, a system fortified with graceful degradation could handle a much higher peak load than an one without it.

About Me
My name is Vladimir Dyuzhev, and I'm the author of GenericParallel, an OSB proxy service for making parallel calls effortlessly and MockMotor, a powerful mock server.
I'm building SOA enterprise systems for clients large and small for almost 20 years. Most of that time I've been working with BEA (later Oracle) Weblogic platform, including OSB and other SOA systems.
Feel free to contact me if you have a SOA project to design and implement. See my profile on LinkedIn.
I live in Toronto, Ontario, Canada. ![]() Email me at info@genericparallel.com
Email me at info@genericparallel.com