March 9, 2015
Transactions in OSB. Reliable Messaging.
How to store-and-forward messages in OSB and never lose them.

In asynchronous mode, a caller disconnects before OSB delivers the message.
If there is a temporary error, OSB has to save the message and retry the delivery later.
How to implement it correctly? What typical mistakes should we avoid?
Requirements for Reliable Messaging
Let’s formalize our needs. We have three parties: a message producer, OSB and a message consumer.
To follow the typical SOA architecture, both message producer and consumer use HTTP to send and receive their messages.
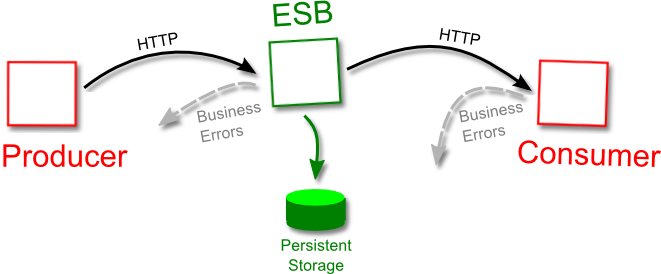
HTTP is not a reliable protocol. Hence, a reliable messaging system have to set a simple contract for each of the three parties that guarantees the reliable message delivery.
Here it is:
Message Producer Rules
The producer can only be confident that the message was received by OSB when OSB responds with HTTP 200.
OSB must persist the message before replying with HTTP 200, and the producer must always check the response code:
| Response from OSB | Explanation | Producer Action |
|---|---|---|
| HTTP 200 and no business error. | The message is accepted for the delivery and _persisted_. | The producer can safely disconnect now. |
| A business error (a service-specific error code). | The message is considered invalid and is NOT accepted for delivery. | The producer should NOT retry. |
| Any system error (HTTP 500 code, timeout, ...). | The message may or may not be accepted for delivery yet. | The producer may retry*. |
(*) Yes, this creates a possibility of duplicate messages - so-called “at least once” guarantee (meaning “once or more”). I’ll show how to deal with it later in the post.
OSB Rules
At any point after the message has been accepted, any eventually recoverable* error (OOM, network errors, JVM crash, …) MUST NOT prevent the message from the delivery when the functioning is restored.
(*) The network can be brought up, the JVM can be restarted. But if a HDD cannot read back the message that was written onto it, is not a recoverable error and you cannot expect any messaging system to recover from it. That kind of problems must be solved on the hardware level (e.g. by implementing RAIDs).
Message Consumer Rules
Just as with Producer-OSB link, the used protocol (HTTP) means sometimes the messages cannot be sent, and sometimes the message is received by the consumer but OSB cannot get the response.
In case of any uncertainty OSB retries the delivery. This is the only way to have “at least once” guarantee implemented over a non-reliable protocol:
| Response from Consumer | Explanation | OSB Action |
|---|---|---|
| HTTP 200 and no business error. | The message is received. | OSB can discard the message. |
| Any business error (a service-specific error code) | The message is invalid and will not be accepted by the consumer, ever. | OSB MUST NOT redeliver and should report and discard the message. |
| Any system error (HTTP 500, timeout, ...) | The message may or may not yet be received by the consumer. | OSB MUST redeliver. |
JMS as a Foundation for Reliable Messaging
Reliable messaging in OSB is implemented over the JMS layer. It already has everything needed, we only have to configure it properly and provide the adapter proxies.
JMS queues
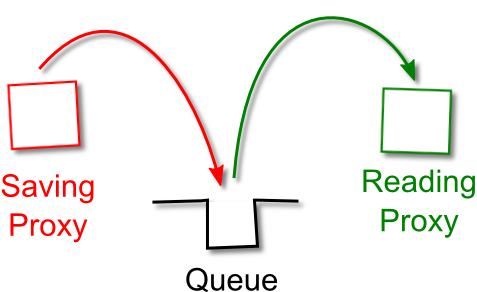
The main building blocks in JMS are queues (and also topics, but they are not for this post).
A queue allows to place a message into it, and then retrieve it from another end. What’s important for reliable messaging, a queue can be persistent, meaning the message is saved in a store that survives the JVM reboot. Typically that store is a special file, but could also be a database.
Transactions
Persistent store along though is not enough. We also need to employ the transactions.
Imagine that OSB is ready to send a message to the consumer. It reads the message from the queue. The message now is in memory, and not on disk anymore. And at that very unfortunate moment the JVM crashes, causing the loss of all in-memory data, including our message.
This is not very reliable!
To prevent this, JMS queues allow to retrieve the message in a transaction.
Only when the reading proxy confirms the message was delivered successfully, the message will be removed from the disk storage. In case of any recoverable error (a fault, even the whole box crash) the message remains in the queue and will be re-processed when the cause of error is corrected.
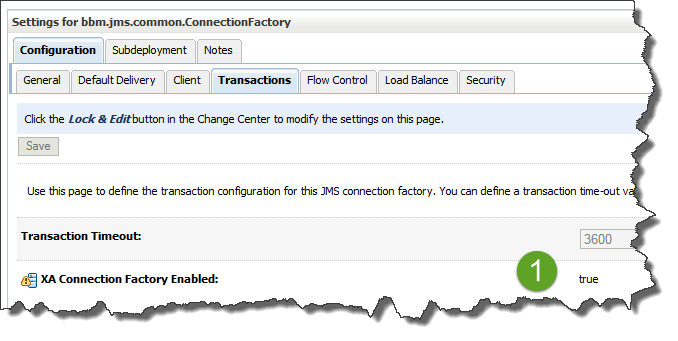
To use a queue in a transactional context, we should connect to it using a connection factory with transactions enabled (so-called XA):
Error Handling
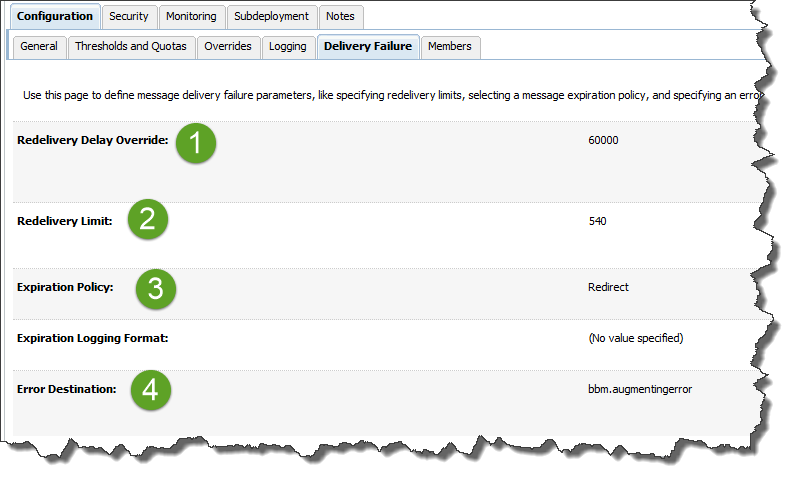
JMS queues allow to configure the retry interval (say, we want to retry every 60 seconds), maximum number of retries and what to do with the message when it is tried for too long.
Our options include just dropping it (not good for our purposes) or placing it into a separate error queue (usually for support to handle it).
Overall Solution Design
Let’s assemble all these parts into one design.
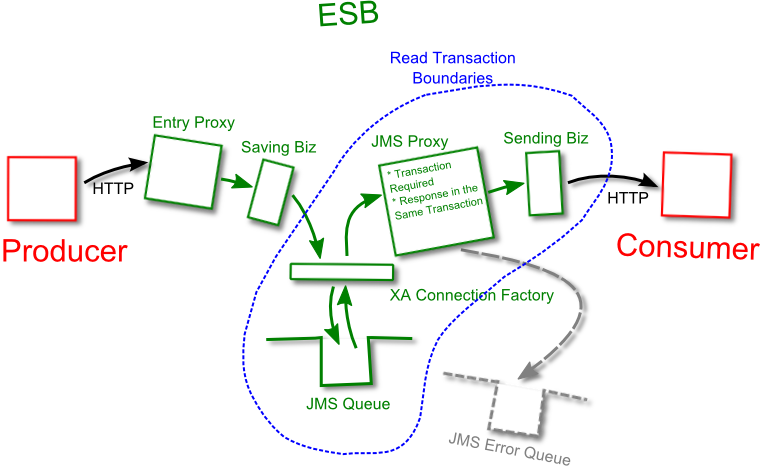
We need to have an entry proxy that receives HTTP requests from the producer. That proxy saves the message into the queue by calling a Biz service (2), and responds to the consumer with HTTP 200. In case of any fault it responds with HTTP 500.
A JMS Biz service places the message into a JMS queue. The service uses a connection factory with XA flag (transactional) set. If the store is not available for any reason (could happen with JDBC-based stores), the transaction will fail and the entry proxy will get a fault.
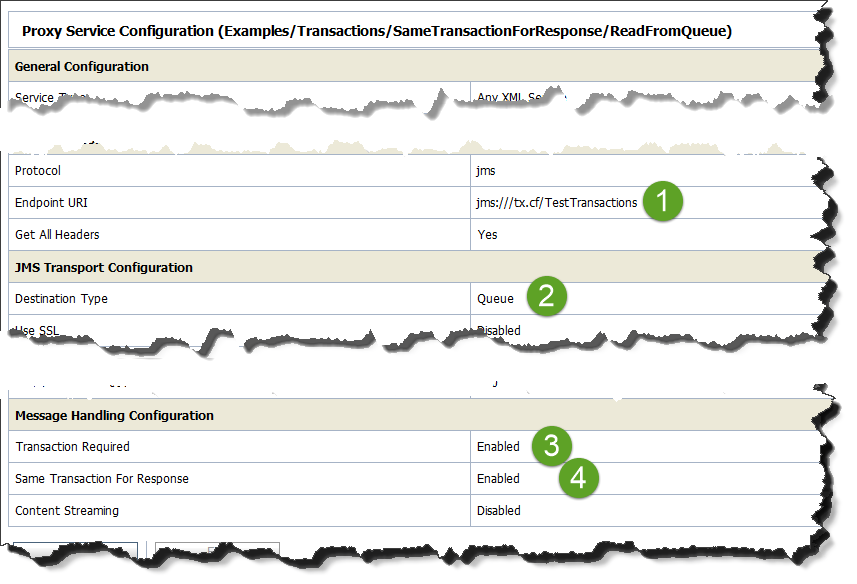
The URL should look like jms:///tx.cf/TestTransactions, where tx.cf is an XA-enabled connection factory, and TestTransaction is the JNDI name of the queue.
- A JMS reading proxy. It uses the same XA connection factory. In addition, it has “Transaction Required” and “Response in the Same Transaction” flags (see below for details).
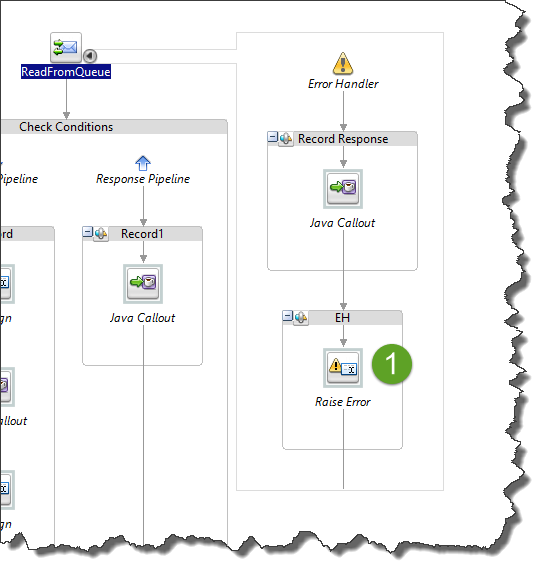
Important implementation detail – it should raise an error in the error handler, if it has one. Reply-with-Error step is not generating a fault and hence does not roll back the transaction:
- A HTTP Biz service that delivers the messages to the consumer. In case of any error it raises a fault and propagates it to the JMS reading proxy (3). The proxy rollbacks the transaction, keeping the message in the queue.
Why Response in the Same Trasaction?
As you can see, the majority of work related to reliable aspect is done in the JMS reading proxy. It has the transaction that guarantees the message is not removed until the consumer receives it.
But why we need “Response in the Same Transaction” flag? Shouldn’t “Transaction Required” be enough?
The answer is in the OSB threading model. The thread that reads the message from the queue and then sends it to the consumer is not the same thread that waits for the response.
Now imagine this scenario:
Thread1 reads the message from the JMS queue.
Thread1 calls the Biz service and sends the message over HTTP.
Now the Thread1’s work is done, it can complete.
Thread1’s transaction commits, too, because Thread1 raised no errors.
Hence, the message is removed from the queue.
Thread2 is waiting for the consumer response.
Thread2 gets a timeout and raises a fault.
But that fault cannot rollback the transaction because it has been already committed!
At this point we do not know if the consumer has received the message (timeout doesn’t give us any information), and we do not have the message in the queue to retry.
To prevent this from happening, Thread2 should be placed into the same transaction as Thread1.
From “At Least Once” to “Exactly Once” by Eliminating Duplicates
As I said already, the HTTP links in our design are not reliable.
Producer has to retry when it is not sure the message has reached OSB, and OSB has to retry when it is not sure the message has reached the consumer.
From time to time, the message does reach the recipient, but the sender cannot tell (due to timeout errors or dropped connections), so the sender performs a retry, and now the recipient has 2 identical messages.
We’re lucky if the messages are idempotent, i.e. their duplicate processing doesn’t cause any problems. For instance, a request to change a user’s phone number can be considered idempotent if received in a short timespan (as it is usually a case with temporal failures).
But what if the messages are not idempotent? What if the message is the proverbial bank transfer note, for instance? We cannot allow for duplicate transfers!
How to deal with it?
The answer is to eliminate the duplicates based on message id.
Every message entering the system must have an unique id. The id is generated by the producer application.
It is important that any retry attempt by the producer uses the same id for a message! Otherwise the same message may enter OSB under different ids, and these duplicates cannot be eliminated.
Sometimes this id could be a natural value from the business domain (say, account# plus the invoice#), but more often the id is generated as a random artificial value.
Eliminating Duplicates on the Consumer
The consumer is expected to have some shared storage, usually a database, where it can check if the message has been processed already. If it was, the duplicate message is just dropped.
The check for duplicates is usually very fast and performed against a DB index.
Eliminating Duplicates on OSB
In the default install, OSB’s managed servers do not have a shared storage. One message instance can be delivered to one managed server, while the second one - to another, and hence OSB cannot detect and eliminate the duplicates.
At the same time, in many configurations OSB is deployed with access to either Coherence or third-party shared in-memory storage.
OSB’s managed servers can place the ids of the messages they see into such storage, and consult it again to check if the message is a duplicate.
The best place to check-and-drop is right before the message is placed into the queue. If the check is moved into JMS reading proxy, every time a message is retried the same id will have to be checked, and the proxy will not know why there is a duplicate – is it because it was already processed by another node or because of the retry?
Typical Mistakes and Tips

Do NOT Use Biz Service Retries
Some people ask me if using retry count in the Biz service configuration is sufficient.
It is not. In fact, it is an easy way to make your service unreliable.
Imagine again that the message is retrieved from the queue and sent to the consumer. Consumer is not available for one reason or another, and Biz service retries the message a few time, but then what? What should it do with the message?
It can only drop it. Even the option to place it into the error queue is not available anymore.
Any JVM-wide error that happens during Biz retries immediately loses the message, too.
I do not even mention that the Biz-based retries are holding a thread, potentially causing the resource exhausting!
Do NOT Re-Insert into Queue in Code
I have seen a code that doesn’t use transactions. Instead, when a fault occurs, it insert the message back into the same queue.
This approach has 3 issues:
First, this messaging is not reliable. If at any moment from the message read to its re-insertion the JVM experiences an OOM or crash, the message is lost forever.
Second, it takes more work and makes the code not as clean as transactional option.
Third, such a code loses Unit-of-Order (UOO), if such order is needed or will be needed in future. The message that was first in the queue, becomes the last.
Keep the Logs Clean
JMS subsystem is rather noisy when you read the logs.
When you use transactions and those transactions have to be rolled back from time to time, logs become inflated with JMS writing long stack-traces into it - the information nobody really needs.
To get rid of those unwanted messages, use Log Filters.
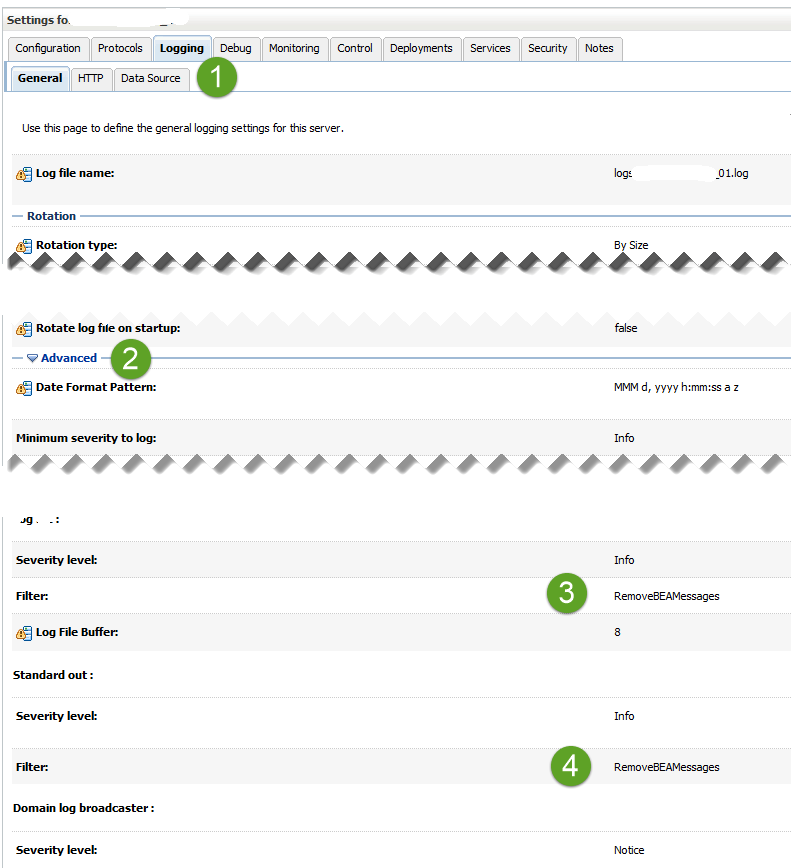
Configure it on the domain page:
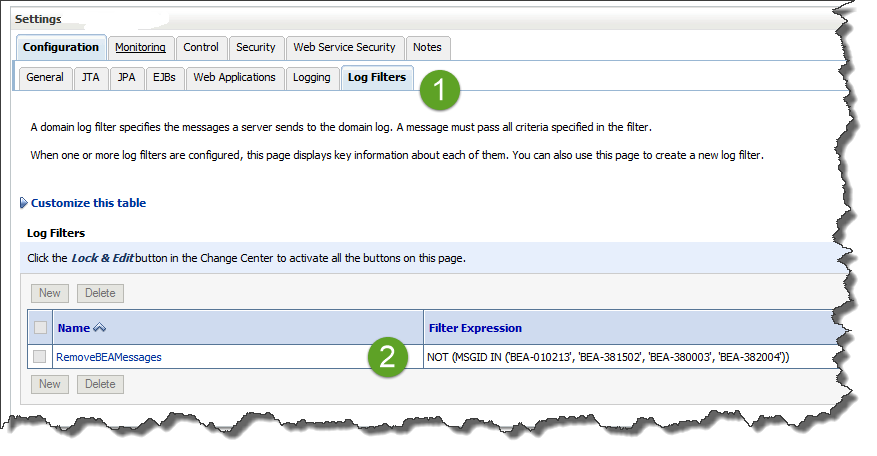
The filter condition there is:
NOT (MSGID IN ('BEA-010213', 'BEA-381502', 'BEA-380003', 'BEA-382004'))
Then assign it to every managed server’s log file, under Logging->General->Advanced->Filter*
{kind=link}
To keep the tab on the system, log the important waypoints for each message id. For example, log “Id 12345 saved into queue”, “Id 12345 sent to consumer”, and so on. Then you’ll always be able to search the logs by the message ID and restore the whole history of the message.
Test Project
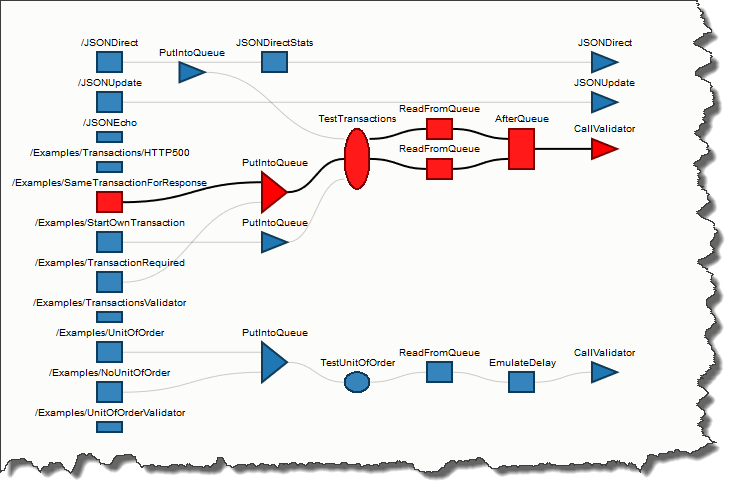
I have implemented a test project that validates the design outlined about.
You can freely download it and play with it.
The package also includes a SoapUI project to test the functionality.
The tests are based on recording the message’s flow through the stages – how many times it got read from the queue (will be multiple times if the transactions are rolled back), and if it reached its final destination – a proxy called Validator.
Feel free to modify it and see how the behaviour of the system changes.

About Me
My name is Vladimir Dyuzhev, and I'm the author of GenericParallel, an OSB proxy service for making parallel calls effortlessly and MockMotor, a powerful mock server.
I'm building SOA enterprise systems for clients large and small for almost 20 years. Most of that time I've been working with BEA (later Oracle) Weblogic platform, including OSB and other SOA systems.
Feel free to contact me if you have a SOA project to design and implement. See my profile on LinkedIn.
I live in Toronto, Ontario, Canada. ![]() Email me at info@genericparallel.com
Email me at info@genericparallel.com